
Why we chose Selenide over Selenium for our Test Automation Needs
Why we chose Selenide over Selenium for our Test Automation Needs

Introduction:
Clipboard Health is in a rapid growth phase and as a result, we’re rapidly iterating and releasing software with a huge number of changes (a recent release included over 30 separate user stories in a 1-week sprint model.) To maintain this speed, it’s very important to have our regression tests automated so the testers don’t spend any unnecessary time on smoke and regression testing. Automation not only helps to save time, but it helps to test repeated tasks effectively and shift our testing further left in the development cycle where fixing defects is less impactful.
We started out using Selenium for our web app and Appium for our mobile apps (built using the Ionic Framework), but eventually found that we were spending a lot of time writing boilerplate code and in other activities that weren’t directly additive to testing our application. We evaluated Playwright as a possible alternative, but the lack of support for mobile native apps was a dealbreaker for us.
In the end, we settled on Selenide, a brilliant wrapper over Selenium that helps to write precise-concise readable tests, and Selenide-Appium, an adaptor for Appium to allow us to test our native mobile apps.
I will highlight some of the important benefits of Selenide over Selenium below.
Reasons for Selenide:
Selenium is a good library, but Selenide provides tooling that makes writing test cases much faster by being an opinionated framework with many built-in methods that eliminates much of the boilerplate we experience.
Brilliant Wrappers provided by Selenide:
In Selenium, we have to create wrapper methods for even simple operations like click, javascript click, and selecting a dropdown. For example, this is a very simple example of how our utils code looks like for the By locator and with the waiting strategy of checking for element presence:
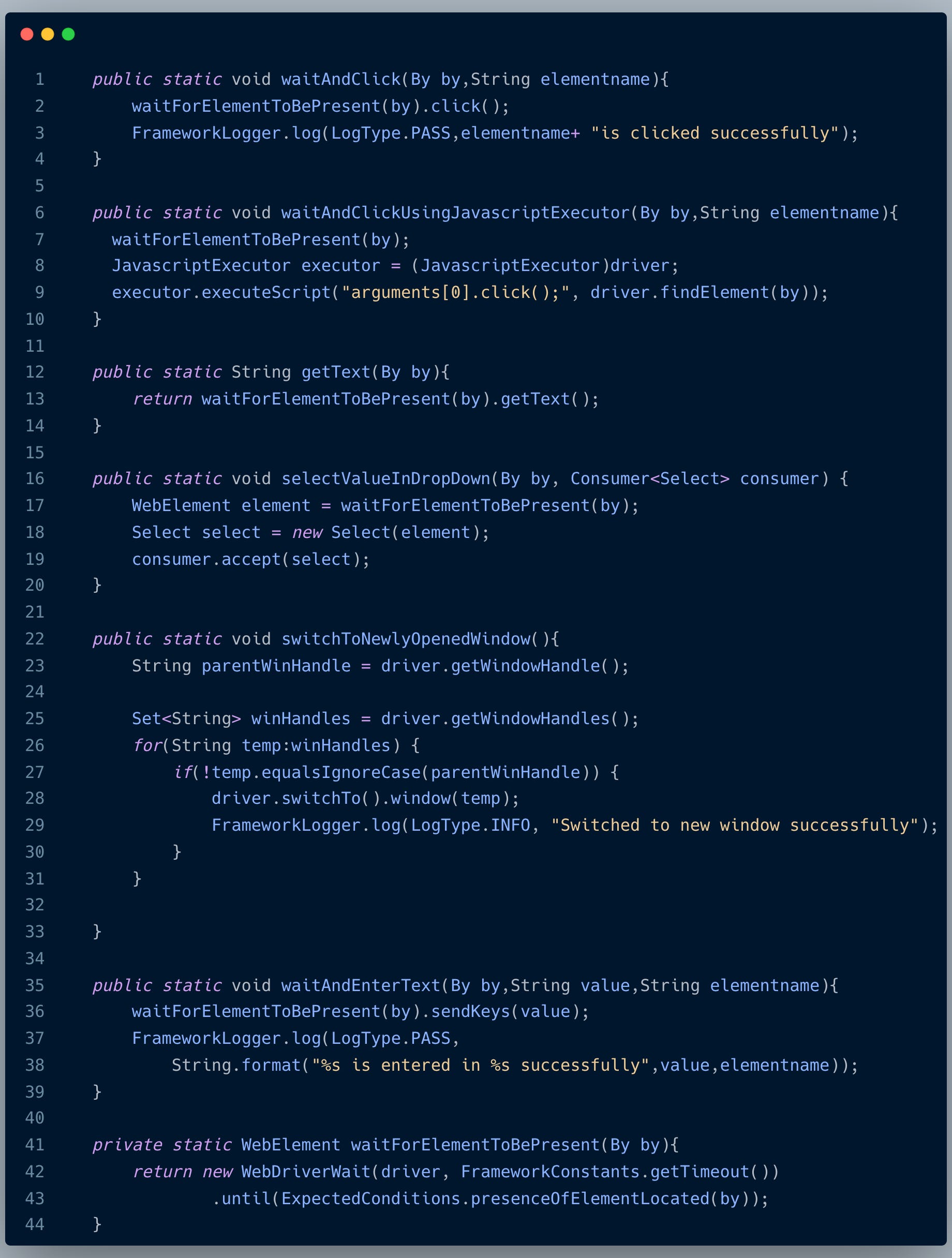
You can imagine the number of overloaded methods we have to create for passing WebElement, different Waiting strategies, different timeouts, corresponding Javascriptexecutor to perform an action, and wrapper methods for selenium actions like upload, download files, switching to windows and frames, getting attributes, etc.
With Selenide, we don’t even have to create a utility class. Yes, you heard that right. Here is what an ideal page method looks like:
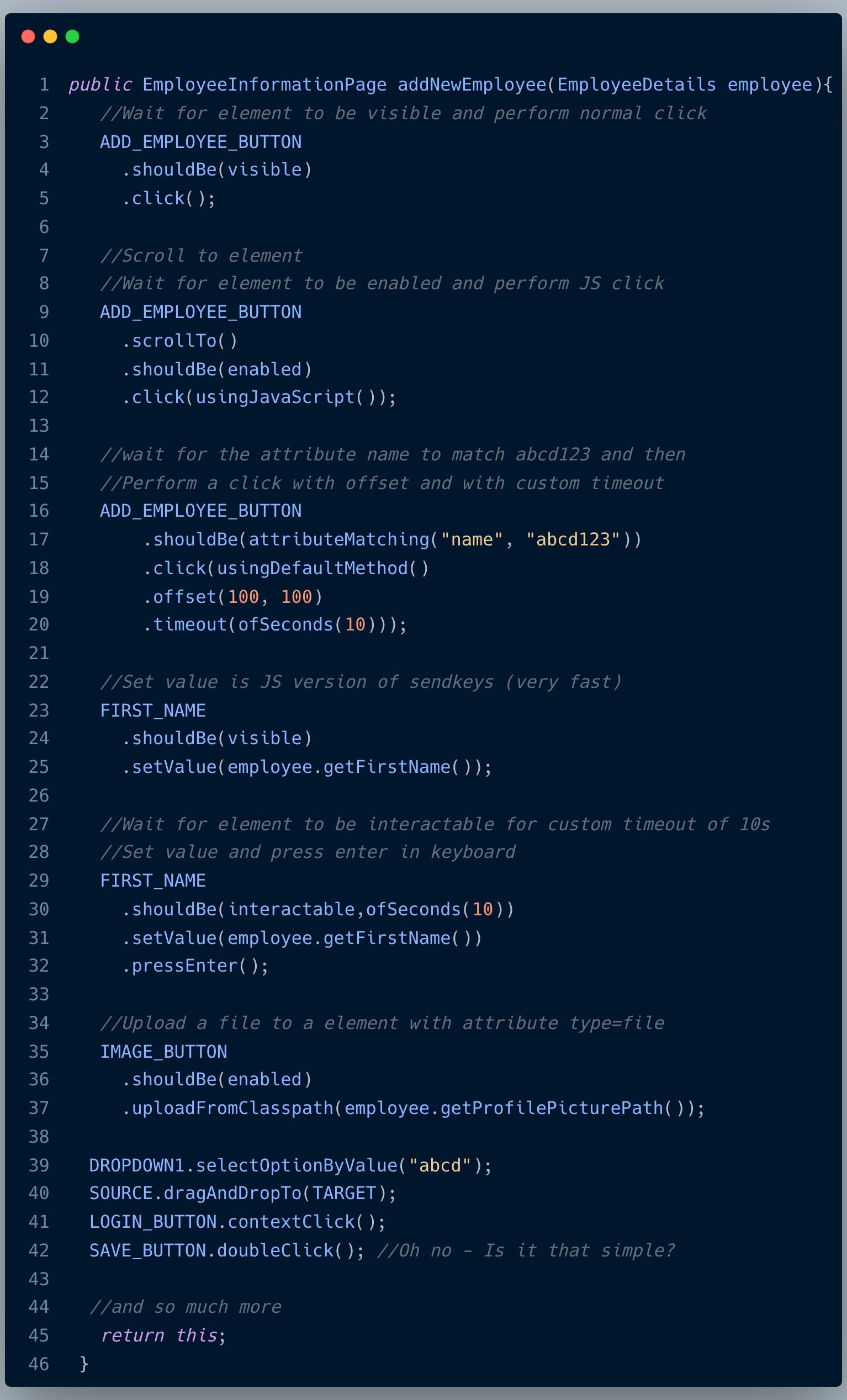
Automatic Handling of Webdriver lifecycle:
In Selenium, we have to manage the lifecycle of Webdriver ourselves. That may seem like a simple task but it can actually take a lot of time to write a working, readable, scalable code.
Setting up the browser, configuring proxies, setting up capabilities, setting default timeouts, managing parallel execution, and closing the browser after execution is a tough task but can be done. But why would we even attempt this when it is already built-in with Selenide?
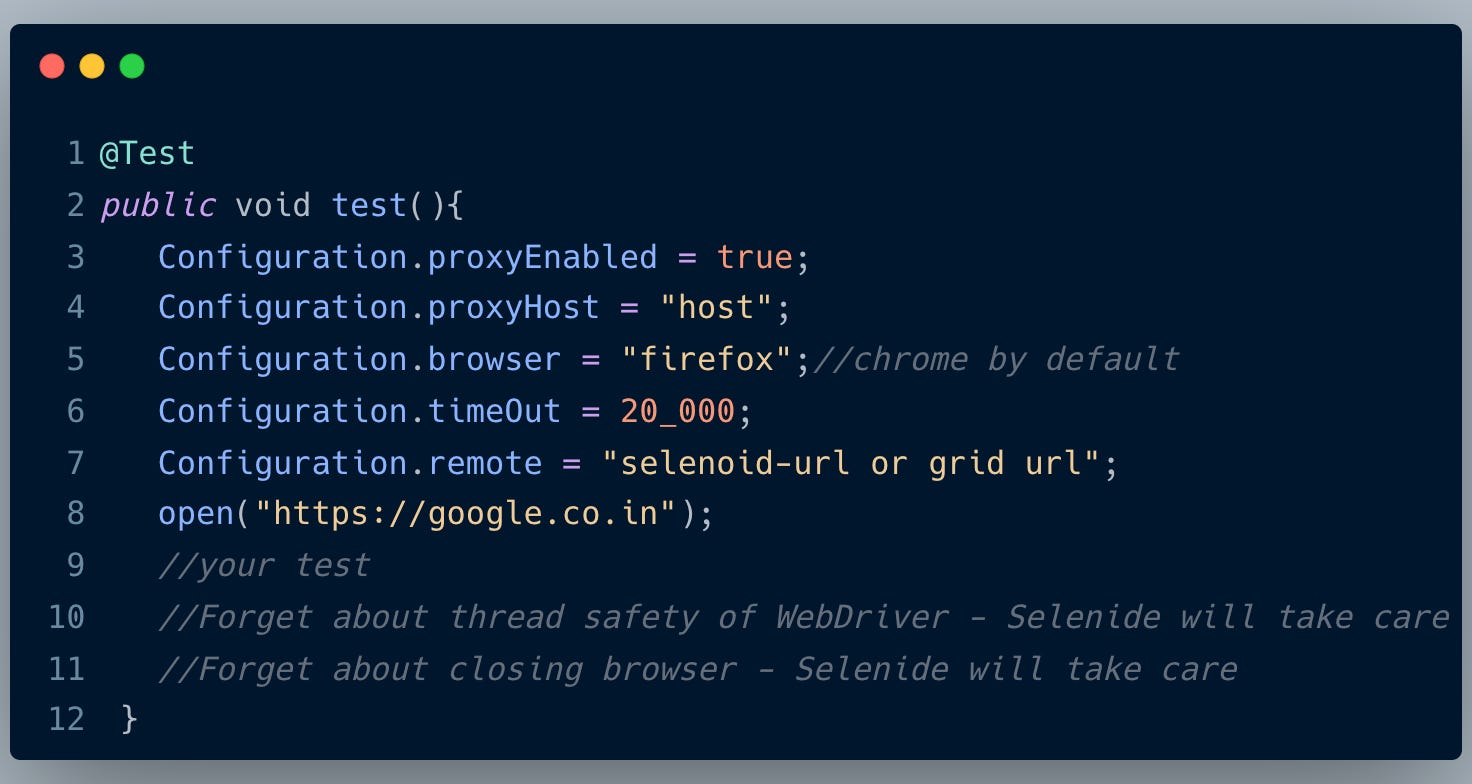
We can also set any of this configuration via selenide.properties or pass it as system variables.
Rich Locators:
Selenide comes with a rich set of locating strategies to find an element. Instead of spending time on the syntax to write an XPath, we can focus on writing the code.
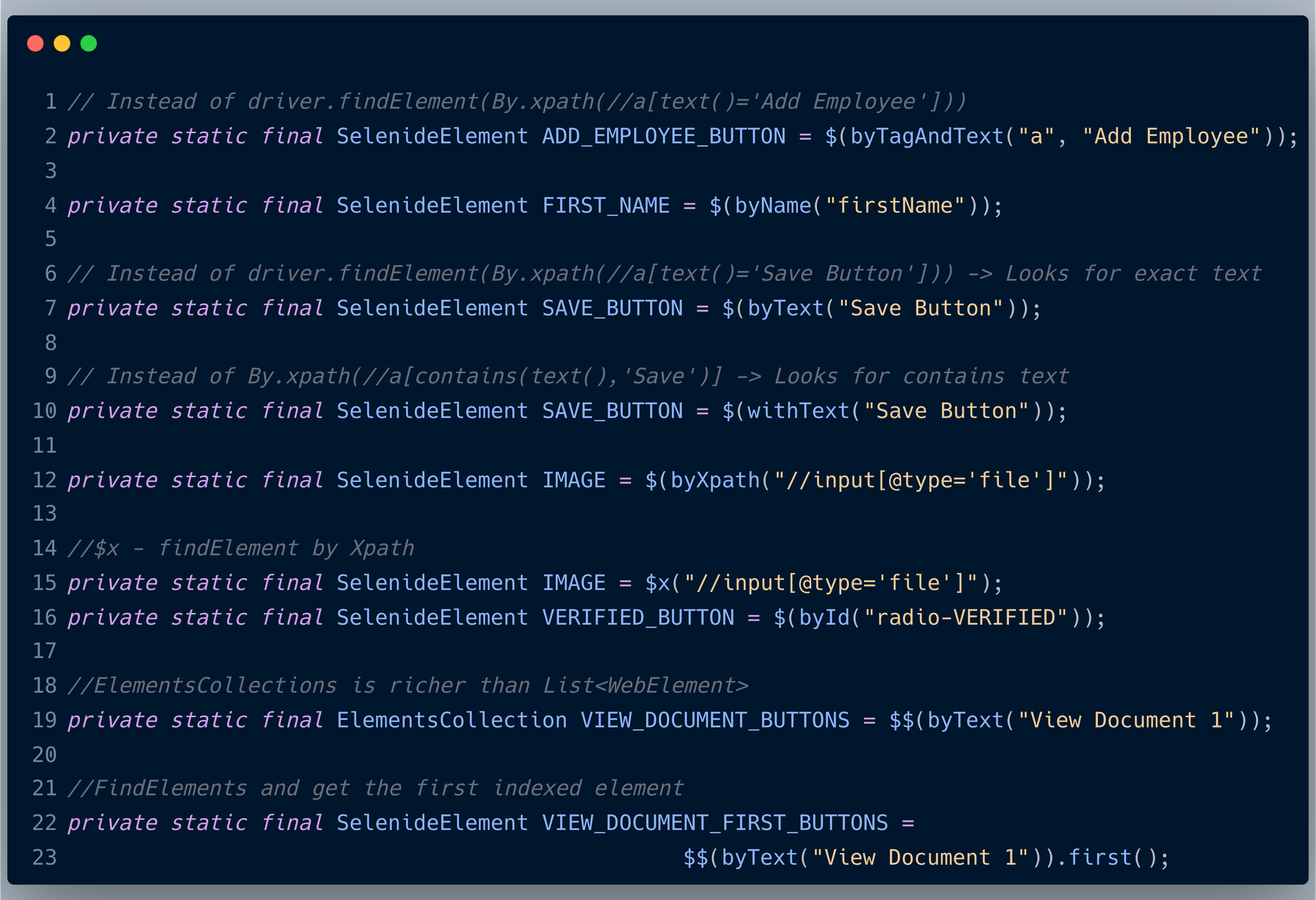
Built-in Reporting and Loggers:
With Selenium, It was necessary to spend a lot of time writing code to generate good and visually appealing reports, not to mention the efforts involved in logging the selenium events to the report. Even if we ignore that extra effort, the code to log selenium events still spoils the code readability.
In case of failure, Selenide captures screenshots automatically and provides a readable and understandable error message. If you want to dig in further, you can use the default reports from Junit and TestNG. But if you still need a report, Selenide offers text reports and integration with allure reports out of the box.
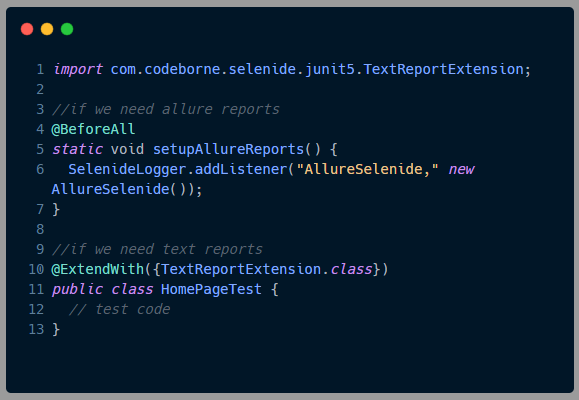
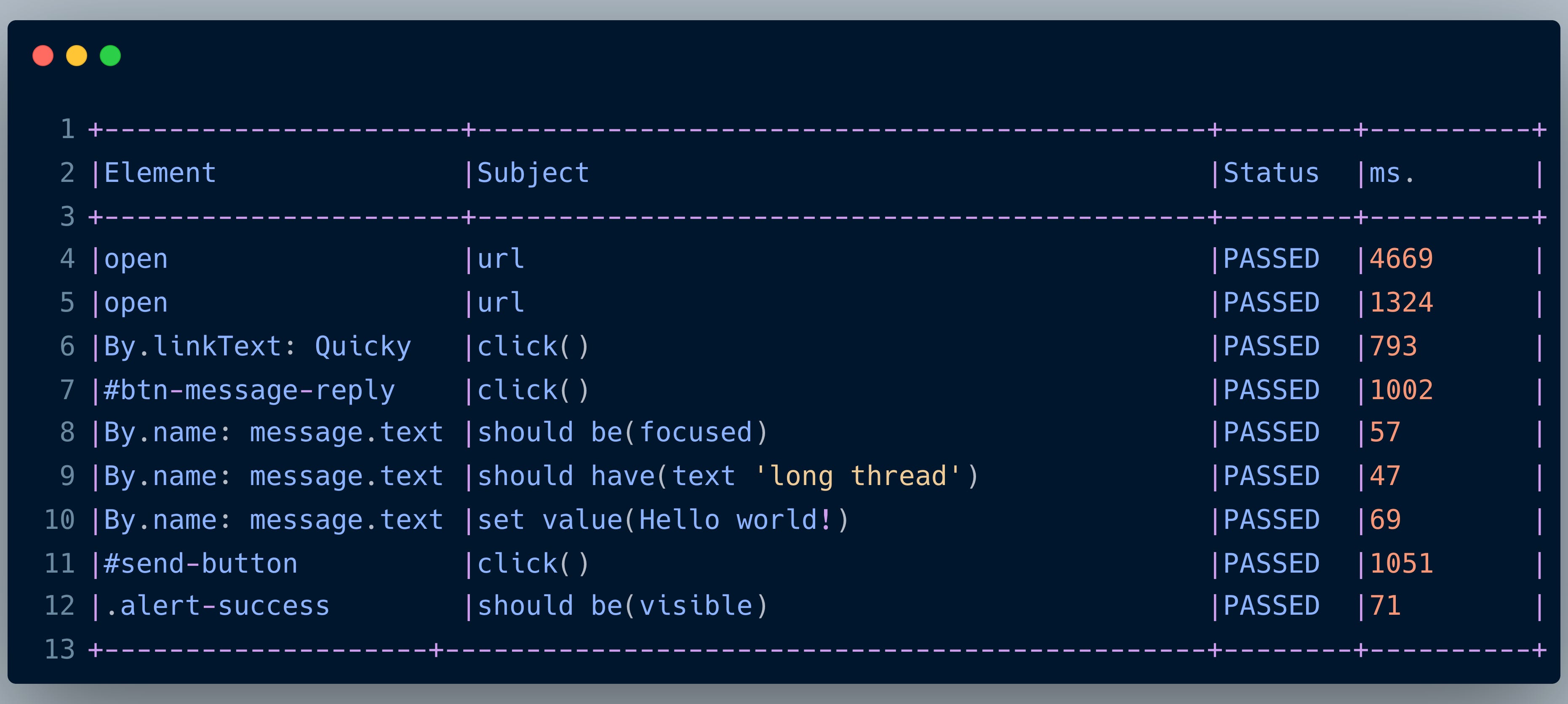
In our project, we decided to go lean and are currently using the Junit report, Selenide text report, and Datadog for historical analysis of tests over a period of time.
Rich Assertions:
Selenium is a brilliant browser automation library but it does not support assertions. We have to rely upon assertion libraries like Junit, TestNG, AssertJ, or Google Truth to satisfy our assertion needs. Most often, this is either not very readable or we have to do a lot of effort to get the information from the web elements and assert it.
Selenide can do this out of the box:
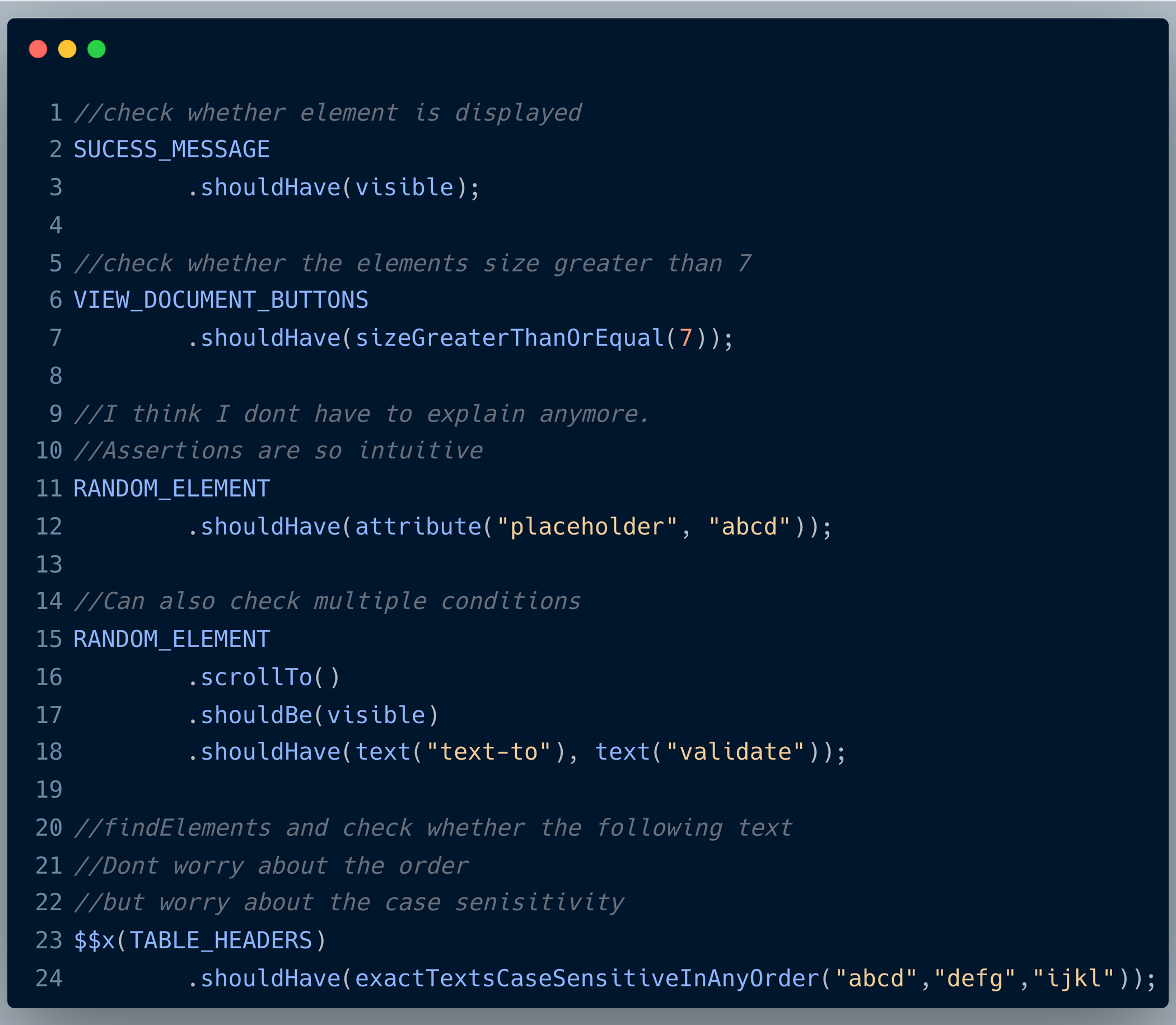
Apart from the aforementioned benefits, Selenide also offers:
Locating Strategies to deal with web tables
Handling shadow dom elements
Basic Auth support for website authentication
Ability to write custom conditions to match our requirement
Handle pseudo-elements
Handle ajax calls, Page Rendering
Fluent and concise API
Not to deal with the Alien StaleElementReferenceException and much more.
Conclusion:
It took only three to four PRs for us to scrap our existing framework and start using Selenide. This has already had a big impact on productivity; we have more robust tests (A total of 28 test cases with a 98 percent success rate - excluding actual defects), and the time taken to automate the tests have drastically reduced. Instead of spending three to four hours to create an automated test, we are now spending roughly 30 minutes.
We all know how much we love Selenium and that makes it harder to choose another wrapper like Selenide. But believe us, the results of using Selenide are well worth it.
Selenide is at least worth a try. Give it a shot -we are sure you will fall in love with it.
 |
|